Reviving ObjectGraph Dictionary
Almost 20 years ago in the early days prior to XMLHttpRequest, web pages would refresh the entire page for every request. I just gave a test in my CS class and needed a data source, I found the 1913 webster’s dictionary dataset which was already copyright expired and in the public domain.
Google Suggest has just come out and I read an article on Apple’s website about XMLHttpRequest and wated to try it out using this dataset. The result was ObjectGraph Dictionary.
In those days CodeProject was a great site to share and I created an article there
https://www.codeproject.com/Articles/9156/Google-Suggest-like-Dictionary

I even used my VISIO skills to come up with a diagram on how it works
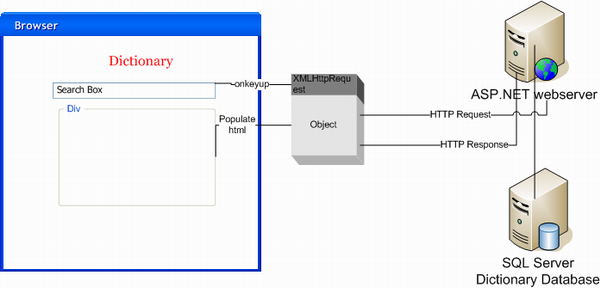
To use the same datasource as before, the original download links were dead, There is a html file with all the words in OPTED here
https://acg.media.mit.edu/people/simong/transfers/dictionary/dictionary.html
Here is my python code to parse it
import json
from bs4 import BeautifulSoup
import re
import sys
import chardet
import logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
def parse_dictionary_html(html_content):
soup = BeautifulSoup(html_content, 'html.parser')
dictionary = {}
skipped_entries = 0
for p_tag in soup.find_all('p'):
try:
b_tag = p_tag.find('b')
if b_tag is None:
skipped_entries += 1
continue
word = b_tag.text.strip()
type_match = p_tag.find('i')
word_type = type_match.text.strip() if type_match else ""
# Extract the meaning by removing the word and type
meaning = p_tag.text
meaning = re.sub(r'^<b>[^<]+</b>', '', meaning)
meaning = re.sub(r'<i>[^<]+</i>', '', meaning)
meaning = meaning.strip()
if word not in dictionary:
dictionary[word] = []
dictionary[word].append({
"type": word_type,
"meaning": meaning
})
except Exception as e:
logging.error(f"Error processing entry: {str(e)}")
logging.error(f"Problematic tag: {p_tag}")
skipped_entries += 1
logging.info(f"Processed {len(dictionary)} unique words")
logging.info(f"Skipped {skipped_entries} entries due to parsing issues")
return dictionary
def detect_encoding(file_path):
with open(file_path, 'rb') as file:
raw_data = file.read()
result = chardet.detect(raw_data)
return result['encoding']
def main():
if len(sys.argv) != 2:
print("Usage: python script.py <path_to_html_file>")
sys.exit(1)
file_path = sys.argv[1]
try:
encoding = detect_encoding(file_path)
logging.info(f"Detected encoding: {encoding}")
with open(file_path, 'r', encoding=encoding) as file:
html_content = file.read()
logging.info(f"Successfully read file: {file_path}")
logging.info(f"File size: {len(html_content)} characters")
except FileNotFoundError:
logging.error(f"Error: File '{file_path}' not found.")
sys.exit(1)
except IOError:
logging.error(f"Error: Unable to read file '{file_path}'.")
sys.exit(1)
parsed_dict = parse_dictionary_html(html_content)
output_file = 'dictionary_output.json'
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(parsed_dict, f, indent=2, ensure_ascii=False)
logging.info(f"Output written to {output_file}")
if __name__ == "__main__":
main()Trie
The original implementation used a SQL server and aspx page for the API which just output html (Just like the new htmx trend). This time around, lets use an in-memory trie to do the job.
A trie stores words as nodes, here is a trie with app and ale

If we insert apple this is how the new structure is

Here is the FastAPI implementation with CORS
import json
from fastapi import FastAPI, Query
from fastapi.middleware.cors import CORSMiddleware
from typing import Dict, List
from contextlib import asynccontextmanager
# Trie node
class TrieNode:
def __init__(self):
self.children = {}
self.is_end = False
self.data = None
# Trie data structure
class Trie:
def __init__(self):
self.root = TrieNode()
def insert(self, word: str, data: List[Dict[str, str]]):
node = self.root
for char in word.lower():
if char not in node.children:
node.children[char] = TrieNode()
node = node.children[char]
node.is_end = True
node.data = data
def search_prefix(self, prefix: str, max_results: int) -> Dict[str, List[Dict[str, str]]]:
node = self.root
for char in prefix.lower():
if char not in node.children:
return {}
node = node.children[char]
results = {}
self._collect_words(node, prefix, results, max_results)
return results
def _collect_words(self, node: TrieNode, prefix: str, results: Dict[str, List[Dict[str, str]]], max_results: int):
if len(results) >= max_results:
return
if node.is_end:
results[prefix] = node.data
for char, child_node in node.children.items():
self._collect_words(child_node, prefix + char, results, max_results)
# Global trie instance
trie = Trie()
def load_dictionary():
global trie
trie = Trie()
with open("dictionary_output.json", "r", encoding="utf-8") as file:
data: Dict[str, List[Dict[str, str]]] = json.load(file)
for word, definitions in data.items():
trie.insert(word, definitions)
print(f"Dictionary loaded with {len(data)} words")
@asynccontextmanager
async def lifespan(app: FastAPI):
# Load the dictionary when the app starts
load_dictionary()
yield
# Clean up resources if needed when the app shuts down
print("Shutting down and cleaning up...")
app = FastAPI(lifespan=lifespan)
# Enable CORS
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # Allows all origins
allow_credentials=True,
allow_methods=["*"], # Allows all methods
allow_headers=["*"], # Allows all headers
)
@app.get("/api/search")
async def search(query: str = Query(..., min_length=1), max_results: int = Query(10, ge=1)):
return trie.search_prefix(query, max_results)
# Endpoint to reload the dictionary
@app.post("/api/reload")
async def reload_dictionary():
load_dictionary()
return {"message": "Dictionary reloaded successfully"}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)Here is my Svelte component for rendering the front end in Astro as my site uses it
<script>
import { onMount } from 'svelte';
let query = '';
let results = {};
let loading = false;
let timeoutId;
let searchInput; // Reference to the search input element
const searchDictionary = async () => {
if (query.length === 0) {
results = {};
return;
}
loading = true;
try {
const response = await fetch(`https://dictionary.objectgraph.com/api/search?query=${encodeURIComponent(query)}`);
results = await response.json();
} catch (error) {
console.error('Error fetching dictionary results:', error);
results = {};
} finally {
loading = false;
}
};
$: {
if (timeoutId) clearTimeout(timeoutId);
if (query) {
timeoutId = setTimeout(() => {
searchDictionary();
}, 300);
} else {
results = {};
}
}
onMount(() => {
// Focus the search input when the component mounts
searchInput.focus();
return () => {
if (timeoutId) clearTimeout(timeoutId);
};
});
</script>
<div class="dictionary-container">
<h1 class="text-3xl font-bold text-center mb-4">Dictionary</h1>
<input
bind:this={searchInput}
type="text"
bind:value={query}
placeholder="Type to search..."
class="w-full p-2 border border-gray-300 rounded-md focus:outline-none focus:ring-2 focus:ring-blue-500 mb-4"
/>
{#if loading}
<div class="mt-2 text-gray-600">Loading...</div>
{:else if Object.keys(results).length > 0}
<div class="bg-white border border-gray-300 rounded-md shadow-sm p-4">
{#each Object.entries(results) as [word, definitions]}
<div class="mb-4">
<h2 class="text-xl font-bold">{word}</h2>
{#each definitions as definition}
<p>
<span class="font-semibold">{definition.type}</span>
{definition.meaning}
</p>
{/each}
</div>
{/each}
</div>
{:else if query}
<div class="mt-2 text-gray-600">No results found for "{query}"</div>
{/if}
</div>
<style>
.dictionary-container {
width: 100%;
max-width: 600px;
margin: 0 auto;
font-family: Georgia, serif;
}
:global(body) {
background-color: #f0f0f0;
}
h1 {
color: #d81b60;
}
h2 {
color: #1565c0;
}
.dictionary-container :global(p) {
margin-bottom: 0.5em;
line-height: 1.4;
}
</style>Here is the final product
https://objectgraph.com/dictionary
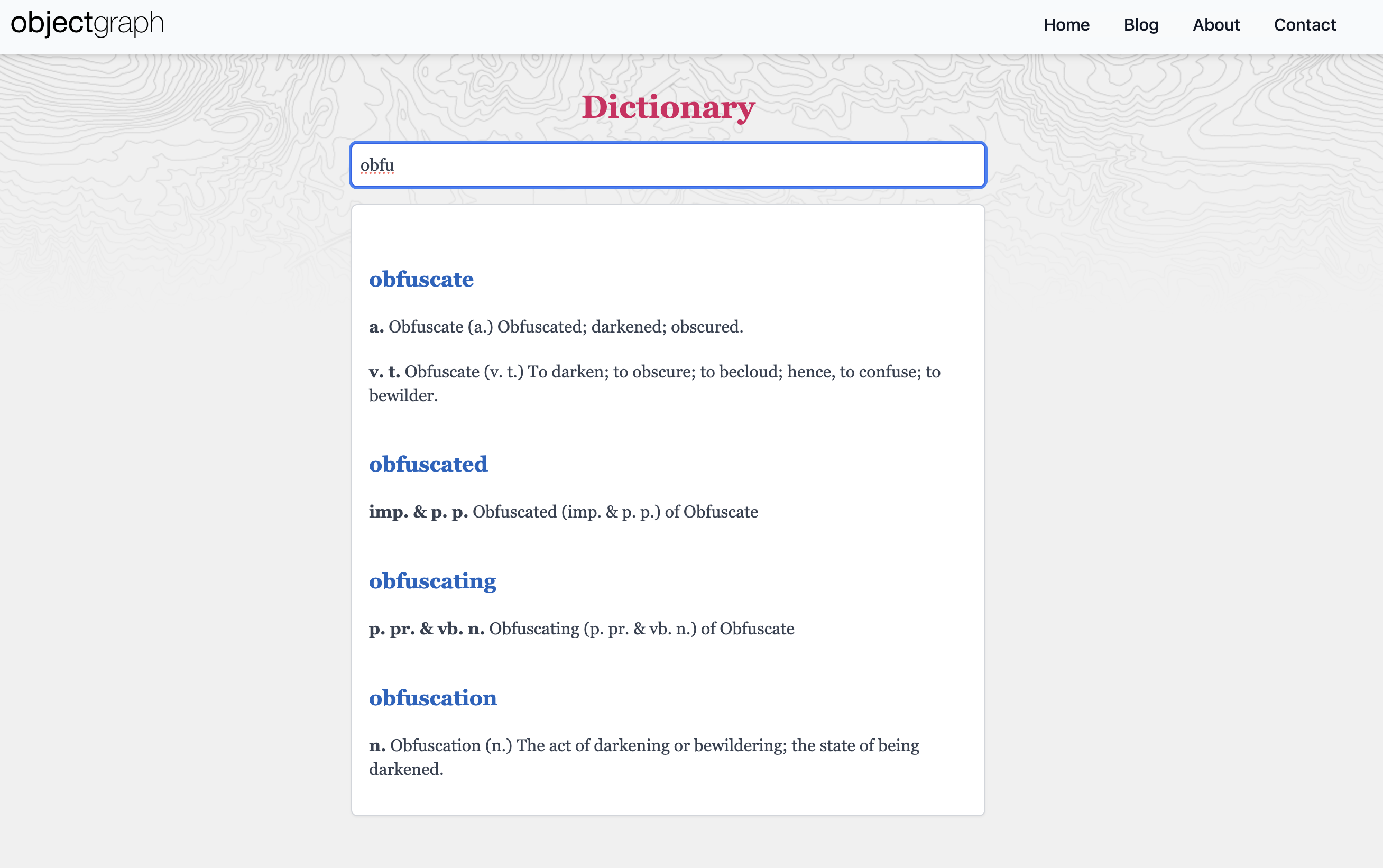
I tried to match the original design
Memory usage:
● gunicorn_dictionary.service - Gunicorn daemon for Dictionary FastAPI application
Loaded: loaded (/etc/systemd/system/gunicorn_dictionary.service; disabled; preset: enabled)
Active: active (running) since Wed 2024-10-02 18:30:36 UTC; 5s ago
Main PID: 105452 (gunicorn)
Tasks: 2 (limit: 2238)
Memory: 237.2M (peak: 237.4M)
CPU: 2.683s
CGroup: /system.slice/gunicorn_dictionary.serviceAs you can see all the dictionary database is in memory at around 237MB, which is not bad.
Performance
Since this API is proxied via CloudFlare, I ran some wrk test and seems like it help up pretty good
Running 30s test @ https://dictionary.objectgraph.com/api/search?query=obfus
12 threads and 400 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 221.90ms 56.66ms 767.94ms 93.83%
Req/Sec 122.74 60.73 303.00 64.77%
32182 requests in 30.10s, 32.93MB read
Socket errors: connect 157, read 0, write 0, timeout 0
Requests/sec: 1069.22
Transfer/sec: 1.09MBOn my local M3 Macbook Pro its super fast, but I think its fine for my EC2 small instance
Running 30s test @ http://localhost:8000/api/search?query=obfus
12 threads and 400 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 40.20ms 6.75ms 143.57ms 98.92%
Req/Sec 498.47 143.67 0.86k 63.93%
178925 requests in 30.10s, 109.38MB read
Socket errors: connect 157, read 108, write 0, timeout 0
Requests/sec: 5944.73
Transfer/sec: 3.63MB